La materialidad de la inteligencia artificial y su costo ambiental
Detrás de las producciones de los grandes modelos de lenguaje de inteligencia artificial generativa como ChatGPT, Gemini, Copilot, Perplexity y Claude, entre otros, existen enormes infraestructuras materiales que sustentan su funcionamiento y tienen un fuerte impacto en el ambiente.
La inteligencia artificial generativa se convirtió en la tecnología de adopción masiva más rápida de la historia. Tanto es así, que ChatGPT, por ejemplo, alcanzó más de un millón de usuarios en solo cinco días después de su lanzamiento el 30 de noviembre de 2022. Aunque las cifras exactas pueden variar, hoy se estima que son varios millones de personas las que utilizan estas tecnologías a diario.
Debido a su presencia transversal en diferentes ámbitos y entornos, podemos decir que la inteligencia artificial generativa es otro actor tecnológico que se suma al ecosistema digital y su entramado sociotécnico.
Durante los últimos treinta años ―aproximadamente― el desarrollo de las tecnologías digitales dio lugar a lo que conocemos como digitalización de la vida, es decir, la producción de enormes volúmenes y variedad de datos generados por nuestras interacciones que fluyen a velocidades increíbles en entornos digitales. Son los llamados datos masivos o big data.
Los seres humanos generamos tantos datos que tuvimos que crear los algoritmos con altas capacidades de cómputo y procesamiento para gestionar semejantes cantidades de datos. Como si esto fuera poco, en los últimos años sumamos los grandes modelos de lenguaje de las inteligencias artificiales generativas, que son entrenados con enormes conjuntos de datos que incluyen textos, imágenes, audios, videos y otros formatos. Estos entrenamientos requieren cada vez más capacidad de cómputo y más espacio para almacenar.
Una nube metafórica
Con el crecimiento de los datos masivos, apareció también el concepto de nube de almacenamiento.
En tecnología, el uso de la palabra nube puede llevar a un error de interpretación ya que evoca la imagen de algo gaseoso y liviano, suspendido en el aire, cuando en realidad el espacio de almacenamiento es muy tangible, concreto y material. La mal llamada nube se trata de la enorme red de servidores de internet conectados entre sí para almacenar, distribuir y gestionar datos. Pero el concepto va más allá del simple almacenamiento y abarca todo un ecosistema de datos, recursos, servicios y aplicaciones informáticas al que se puede acceder de forma remota.
Estas extensas redes de servidores se encuentran en gigantescos centros o almacenes de datos distribuidos en lugares físicos por todo el mundo; tanto bajo el agua ―a través de 450 cables submarinos de internet que conectan puntos estratégicos del planeta― como en miles y miles de estructuras terrestres monumentales alojadas en diversos países que albergan otros miles de servidores y cables. Además, el diseño modular de los centros de datos les permite a las empresas una expansión continua, por lo que añaden más servidores y capacidad de almacenamiento según sea necesario.

¿Cómo es un megacable submarino?
Marea es el nombre de un cable submarino que comenzó a funcionar en 2018 y se extiende 6.600 kilómetros de longitud a lo largo del océano Atlántico, tendido entre Virginia Beach (Estados Unidos) y Sopelana (Vizcaya, España). Se trata de uno de los cables más largos y avanzados del mundo, pesa aproximadamente 4,65 millones de kilogramos y transporta enormes cantidades de datos, con una velocidad de transmisión de 160 terabits por segundo (Tbit/s).
La materialidad del cable es evidente desde el momento en que para fabricarlo se necesitaron miles de kilómetros de fibra óptica, recubiertos de materiales resistentes al agua salada y protegidos por múltiples capas de acero. Durante el ensamblaje, equipos de buzos y robots submarinos trabajaron en condiciones extremas para asegurar que el cable quedara perfectamente anclado al lecho marino. La instalación, realizada por la compañía Telxius, requirió operadores con gran experiencia, una flota de barcos especializados y una inversión millonaria por parte de las empresas propietarias del megacable: Microsoft y Meta.
Cada vez que enviamos un correo electrónico, utilizamos el GPS o realizamos una videollamada transatlántica, por ejemplo, los datos fluyen a través de ese cable.

Video de la construcción del cable submarino Marea. Duración: 1 minuto.
¿Cómo es un centro de datos terrestre?
Uno de los tantos centros terrestres de datos que tiene Google se encuentra en The Dalles, Oregón, Estados Unidos, en una ubicación estratégica a orillas del río Columbia. Esta megaestructura es conocida por su tamaño y capacidad, que alberga múltiples edificios, cada uno diseñado para maximizar la eficiencia y la seguridad de los datos almacenados.
Tiene una capacidad operativa impresionante; aunque Google no publica cifras exactas sobre la cantidad de servidores o la capacidad total de almacenamiento, se sabe que este centro de datos es uno de los más grandes y avanzados del mundo, con miles de servidores que gestionan increíbles cantidades de datos diariamente.

El funcionamiento de un centro de datos de esta magnitud requiere una combinación de tecnologías sofisticadas y prácticas de gestión de la energía. Estas prácticas producen impacto ambiental por el uso de recursos naturales y por la contaminación.
Pensemos, por ejemplo, en la refrigeración para operar un coloso de esta envergadura. Uno de los mayores desafíos en la operación de un centro de datos de semejante escala es la gestión del calor excesivo generado por el uso de enormes cantidades de electricidad. En The Dalles, por ejemplo, Google instaló torres de enfriamiento que utilizan las aguas del río Columbia para refrigerar todos los equipos involucrados y reducir la temperatura. El río es un recurso natural público y su usufructo, por empresas privadas, genera una presión hídrica crítica para la zona, además de contaminación.
El centro de datos en The Dalles es solo uno de los 600 centros de datos de hiperescala operados por grandes compañías como Google, Amazon, Meta y Microsoft. Pero, si consideramos todos los tipos de centros de datos, incluyendo los más pequeños, el número es mucho mayor.

Tecnologías generativas, electricidad y agua
Todas las grandes empresas propietarias de megacables y centros de datos masivos afirman que hacen un uso responsable de los recursos naturales y tienen un compromiso con la reducción de la huella de carbono.
La huella de carbono es una medida que evalúa el impacto ambiental de una actividad o producto en términos de emisiones de gases de efecto invernadero (GEI), especialmente dióxido de carbono (CO2). Como explicamos, esta huella está directamente relacionada con el consumo eléctrico que requiere la gestión de datos masivos ―entre ellos, el entrenamiento/funcionamiento de los grandes modelos de lenguaje― y con la refrigeración que los centros de datos necesitan para evitar el sobrecalentamiento. El enfriamiento requiere enormes cantidades de agua, lo que afecta los recursos hídricos locales.
El consumo de agua relacionado con el uso de inteligencia artificial generativa es un tema que cada día preocupa más. Dos ejemplos pueden revelar el porqué de las preocupaciones:
- Durante 2023, los centros de datos de Google consumieron casi 20.000 millones de litros de agua, lo que representa aproximadamente un 10 % del consumo anual de agua que tiene un país como España.
- Una conversación de aproximadamente 20 preguntas y respuestas con ChatGPT consume el equivalente a medio litro de agua (500 ml).
Estas cantidades son preocupantes si consideramos que el planeta atraviesa una crisis de agua dulce potable para cubrir las necesidades básicas de los seres humanos.
En la columna Futuro Imperfecto número 24 de la Revista Jotdown en español, Martín Sacristán explica:
Para usar lo que llamamos, genéricamente, internet, necesitamos tanta agua o más que la agricultura de regadío. Es un fenómeno reciente, muy nuevo, cuyo inicio podemos fijar en 2017, año en que su crecimiento exponencial empezó a ser motivo de preocupación. El motivo lo señala indirectamente el irlandés Gerry McGovern, uno de los mayores expertos en gestión de contenidos en internet, en su libro World Wide Waste. Allí explica que el 90 % de los datos creados en toda la historia de la humanidad se originaron entre 2017 y 2019. Hablamos de datos digitales, y no es casual que a esa producción masiva le siguiera un gran desarrollo de la inteligencia artificial, porque pudo entrenarse con ellos. Su acceso vía internet lo posibilitaron los servicios en la nube, que funcionan gracias a centros de datos físicos: grandes infraestructuras de servidores que se calientan, necesitan ser enfriados, y que han incrementado exponencialmente su consumo hídrico. En 2022 Microsoft empleó un 34 % más de agua, y Google, un 20 %. Estas empresas atribuyen el incremento a la implantación del uso de la inteligencia artificial, tanto por el entrenamiento de modelos como por el uso público. Es apenas un pequeño aperitivo de lo que viene.
Todos los centros de datos distribuidos por el mundo contaminan, generan huella de carbono, huella hídrica y modifican el ambiente donde se establecen. Sus instalaciones materiales tienen costos ambientales locales, regionales y globales.
La periodista Isabel O'Brien publicó una investigación en The Guardian donde afirma:
Las emisiones de los centros de datos probablemente sean un 662 % mayores de lo que afirman las grandes tecnológicas. ¿Podrán mantener el engaño? Las emisiones de los centros de datos internos de Google, Microsoft, Meta y Apple podrían ser 7,62 veces mayores que el recuento oficial.
La industria de los centros de datos emitirá 2500 millones de toneladas de dióxido de carbono (CO2) en el año 2030.

Fabricación de tecnología generativa
Otra forma de materialidad de las tecnologías de inteligencia artificial generativa que tiene un impacto negativo en el ambiente está relacionada con la fabricación de dispositivos de IA que requiere metales pesados y productos químicos tóxicos. Algunos centros de datos utilizan baterías de metales pesados y refrigerantes peligrosos que contaminan el suelo y las napas subterráneas.
La extracción de materias primas fundamentales para la IA y la instalación de nuevos centros de datos, construcción de instalaciones y fabricación de equipos generan la sobreexplotación de recursos naturales, arruinan los ecosistemas de la zona y causan problemas de contaminación.
Cada respuesta generada por los grandes modelos de lenguaje, cada prompt en un chat conversacional, tiene un costo ambiental asociado.
Atlas de inteligencia artificial
Atlas de inteligencia artificial, libro escrito por la científica australiana Kate Crawford, es una investigación exhaustiva que explora la materialidad y los costos planetarios asociados a la inteligencia artificial generativa.
A lo largo de 20 años de trabajo, Crawford analizó la extracción de datos a gran escala y cómo esta afecta tanto al ambiente como a las estructuras de poder. La investigadora no elaboró un atlas geográfico convencional, aunque el título de su libro evoca la idea de cartografía y exploración, sino que, en lugar de mapas geográficos, Crawford elaboró un mapa conceptual impresionante que revela la materialidad oculta detrás de la inteligencia artificial.
Dos aspectos clave que Crawford mapea en el libro:
- Costos para el planeta y para los individuos. La autora analiza el costo material de la extracción de datos, incluyendo la explotación de minas de tierras raras, recursos subvencionados y la explotación de mano de obra. Y subraya que la IAGen no es solo una abstracción, sino que tiene un costo ambiental real, desde la extracción de recursos hasta la gestión de residuos electrónicos. También examina cómo la IAGen perpetúa sesgos sociales y culturales y cómo los estados y empresas privadas evaden responsabilidades en la extracción y tratamiento de información privada.
- IAGen: ni inteligente ni artificial. Crawford argumenta que la IAGen no es ni verdaderamente inteligente ni completamente artificial porque está arraigada en el mundo físico. La IAGen no es solo código, sino una red compleja de procesos materiales tejida con hilos de datos, energía, mano de obra y lógicas económico-políticas.
Crawford también desarrolló, junto a Vladan Joler, un trabajo muy importante titulado «Anatomía de un sistema de IA. Amazon Echo como mapa anatómico del trabajo humano, los datos y los recursos planetarios», abierto para navegar y consultar en anatomyof.ai.
Por su parte, Taller Estampa ―que es un colectivo de artistas, programadores e investigadores de Barcelona― desarrolló una cartografía de la inteligencia artificial generativa en la cual expone todos los componentes, vínculos y territorios materiales involucrados en el funcionamiento de las IAGen. «¿Qué conjunto de extracciones, agencias y recursos nos permiten conversar en línea con una herramienta generadora de textos u obtener imágenes en segundos?», plantea Taller Estampa.
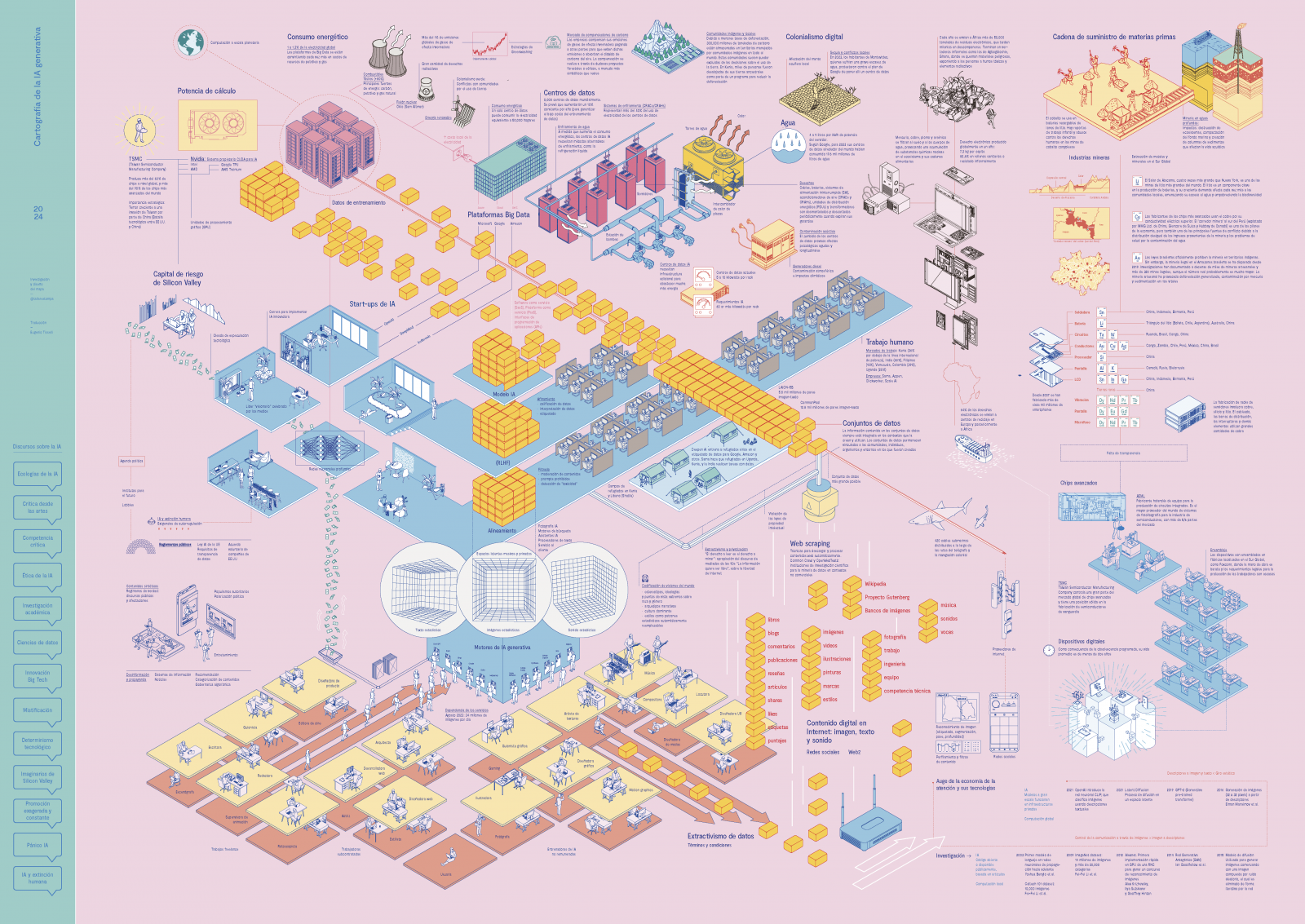
La materialidad de las tecnologías de inteligencia artificial generativa es palpable y tangible. Detrás de las palabras que leemos en pantalla, hay cables, servidores, centros de datos y una infraestructura masiva. Como sociedad, debemos considerar tanto los beneficios de las IAGen como las consecuencias negativas sobre nuestro hábitat social y ambiental para tomar decisiones informadas, responsables y éticas.
Notas de accesibilidad
Descripción detallada de la infografía sobre centros de datos por país
Estados Unidos, el país con más data centers. Número de centros de procesamiento de datos por país en 2023.
- Estados Unidos: 5.376
- Alemania: 522
- Reino Unido: 517
- China: 448
- Australia: 306
- México: 166
- Brasil: 163
- India: 151
- España: 140
Datos del 16 de octubre de 2023. Países seleccionados. Fuente: Cloudscene.
Volver a la infografía sobre centros de datos por país
Recomendados

Inteligencia artificial: de la ciencia ficción a la realidad
Texto
Hace apenas unas décadas, las promesas de la inteligencia artificial (IA) parecían circunscriptas a las especulaciones de la ciencia ficción. Hoy, nos encontramos en un mundo donde la rápida evolución de la IA está generando grandes cambios en muchos aspectos de nuestras vidas. ¿Qué es la IA? ¿Cómo funciona? ¿De qué maneras podemos usarla?

Inteligencia artificial: anatomía de un buen «prompt»
Texto
¿Por qué podemos conversar con una inteligencia artificial generativa sin tener conocimientos de programación? Porque la interfaz de la IAGen tiene un diseño muy simple en forma de chat que solo requiere el tipeo de un prompt en un cuadro simple. Una vez tipeado ese prompt, que puede ser una pregunta o una indicación, la IAGen ofrece una respuesta inmediata.

Sesgos, citas falsas y alucinaciones: fallas en la inteligencia artificial
Texto
La opacidad en el funcionamiento de la inteligencia artificial se debe principalmente a la intención de las empresas desarrolladoras en resguardar los procesos internos de sus algoritmos y no revelar cómo funcionan. Esta falta de transparencia nos pone en alerta y demuestra la necesidad de pensar críticamente en los sesgos, las citas falsas, las alucinaciones y la soberanía tecnológica.
Ficha
Publicado: 09 de septiembre de 2024
Última modificación: 20 de mayo de 2025
Audiencia
General
Área / disciplina
Educación Digital
Cultura y Sociedad
Nivel
Primario
Tercer Ciclo
Secundario
Superior
Categoría
Artículos
Modalidad
Todas
Formato
Texto
Etiquetas
inteligencia artificial (IA)
cultura digital
tecnología digital
Autor/es
Carina Maguregui
Otros contribuyentes
Educ.ar
Licencia
Creative Commons: Atribución – No Comercial – Compartir Igual (by-nc-sa)