Inteligencia artificial, ¡no te tenemos miedo!
En este taller, se invita a explorar, mediante una serie de juegos, de qué hablamos cuando hablamos de inteligencia artificial. Para ello, se propone reflexionar y debatir sobre diversos conceptos, tales como algoritmos, patrones, sesgos y huella digital para finalizar con el diseño de una carta abierta sobre su uso responsable.
Sobre la propuesta
La inteligencia artificial (en adelante, IA) se integra de manera casi imperceptible en nuestro hacer cotidiano. Usamos 一o experimentamos一 sistemas inteligentes casi a diario, por ejemplo, cuando nuestro email detecta correo basura (spam), cuando acudimos a servicios de traducción de idiomas en línea (Google, DeepL), cuando recorremos la ciudad (Google Maps, Waze), cuando buscamos información en la web (Google, Yahoo), cuando compramos en línea (Amazon, Mercado Libre) o cuando usamos sistemas de recomendación (Spotify, Netflix, YouTube), entre otras situaciones.
En este taller nos proponemos explorar, mediante una serie de juegos, de qué hablamos cuando hablamos de IA.
Objetivos
-
Reflexionar y debatir sobre el concepto de la IA: su funcionamiento, las transformaciones que puede generar, los desafíos y responsabilidades que conlleva su uso.
-
Entender el funcionamiento y la responsabilidad de cómo se debe entrenar a una máquina teniendo en cuenta el concepto de «patrones».
-
Promover la diversidad e inclusión de género en el ambiente tecnológico a través del concepto de «sesgo».
-
Reconocer cómo funcionan los algoritmos y la creación de un modelo en el entrenamiento de una máquina.
-
Diseñar una carta abierta a las personas que entrenan máquinas sobre el uso responsable de la IA.
Actividades
Primer momento: ¿Qué sabemos de la IA?
Empezamos a realizar algunas preguntas exploratorias para que los y las estudiantes puedan comentar, a partir de sus propias experiencias, lo que saben y no saben sobre la IA. Estas son algunas preguntas posibles:
¿Qué saben o conocen de la IA?, ¿les da miedo?, ¿les da curiosidad? La IA está en boca de todo el mundo, pero poca gente sabe lo que es. ¿Cómo funciona? ¿Hasta dónde puede llegar? ¿Cuáles son sus limitaciones? ¿Dónde se ve o dónde intuyen que funciona la IA?
Luego, sugerimos reflexionar sobre las distintas respuestas y preguntar si se les ocurren algunos ejemplos. Se puede debatir sobre los ejemplos que vayan apareciendo, y hacer foco en alguno que sea más conocido y utilizado por los y las participantes. Para mencionar algunos de los más populares, tomemos el caso de Netflix, Amazon o Instagram. Se trata de entender que diariamente interactuamos con la IA de múltiples maneras y sin darnos cuenta.
Podemos preguntarles: ¿comprenden cómo trabaja Instagram? ¿Notan algo cuando Netflix les hace una recomendación? ¿Pueden descifrar cuál es el proceso que subyace a dicha recomendación o cómo la plataforma llega a ella?
Como producto de esta conversación, seguramente surjan varias ideas que se pueden aprovechar para vincular con ciertas nociones. Por ejemplo, el concepto de «huellas digitales», que es una metáfora para nombrar la información que dejamos en las plataformas al usarlas. Las huellas son datos que dejamos de modo indirecto y muchas veces involuntaria e inadvertidamente. Los programas de IA trabajan con esos datos, van aprendiendo, se van «entrenando» y entregando respuestas (recomendaciones, ofertas) a partir de esa información. Hasta un tweet o un posteo pequeño es «alimento para la IA». Si bien en esta instancia no se va a explicar el proceso con detalle, la idea es que se comprenda que la tecnología toma la información que los mismos usuarios y usuarias proveemos. La IA no es crítica. Lo que la IA crea no es un producto original, nuevo, sino que es siempre la combinación de elementos preexistentes aportados por personas.
A partir de los intercambios, el/la docente puede ir construyendo las respuestas a las preguntas arriba planteadas, a modo de conclusiones. Sugerimos escribir estas conclusiones con la herramienta TTSMaker para poder, una vez finalizado el taller, escuchar en voz alta lo que se ha ido comentando y, a la vez, socializarlo.
Segundo momento: Juguemos a entrenar una máquina
Les proponemos jugar a Inteligencia artificial para océanos de la Fundación Code.org. Pueden hacerlo a través de este enlace: https://studio.code.org/s/oceans/lessons/1/levels/2?lang=es-MX

El sitio está en inglés y puede traducirse a través de un cambio que se encuentra abajo, a la izquierda.
El primer desafío es identificar una figura en particular: peces. En la página veremos que hay una base de datos ya dada de peces y de otros elementos que se encuentran en el mar que no son peces sino desechos (carozos de manzanas, botellas de plástico, latas, etc.). El mecanismo del juego es ir señalando: «esto es un pez», «esto no es un pez». Así hasta un número que, en principio, puede ser 30. El contador se encuentra arriba, a la derecha.
Una vez entrenada la máquina con un número de casos definido previamente, se puede poner en marcha el robot y se observa cómo identifica los casos, es decir, cómo reconoce qué es un pez y qué no lo es. Es importante señalar que el programa realiza este reconocimiento a partir de la información que le dimos, y asimismo que, en algunos casos, el reconocimiento es erróneo. Estas observaciones deben ser anotadas para retomarlas en la conversación final.
Luego de haber experimentado el juego, es bueno generar una conversación sobre los siguientes temas.
-
¿Qué hicimos? Durante el juego hemos enseñado al robot lo que queremos que él aprenda a identificar: cómo es un pez. Indicando repetidamente (con imágenes en este caso), qué es un pez y qué no lo es, el robot va aprendiendo. Le mostramos muchas imágenes con peces y otras sin peces (datos de entrenamiento) y vamos apretando el botón correcto. Esto se hace con las características positivas, pero también con las características negativas: por eso se muestra, se enseña qué «es pez» y que «no es pez».
-
Es importante subrayar la cantidad y calidad de información que proveemos. Si le mostramos correctamente, sin errores, qué es un pez y le brindamos una gran cantidad de datos, nos aseguramos respuestas más correctas del robot. A mayor cantidad de datos 一que le sirven para corroborar y confirmar一 mayor la posibilidad de que no se equivoque.
-
Aprendizaje supervisado. En este caso, hemos experimentado con el aprendizaje supervisado, ya que los datos con los que vamos a entrenar nos fueron dados. No fuimos nosotros/as quienes cargamos las imágenes de peces, deshechos, etc. La IA deberá entrenarse en esos datos para saber qué se quiere identificar y conformar su propia base.
-
El concepto de patrones. El robot de nuestro juego digital está siendo entrenado y va aprendiendo a través de la creación de patrones. El robot va identificando, aprendiendo, «anotando» que son peces aquellos que, por ejemplo, tienen ojos o tienen aletas y no aquellos que son de plástico o de metal.
Lo que hemos hecho en las actividades fue enseñarle al robot a identificar un objeto o animal específico a partir de una base de datos que lo contiene junto a otras cosas u objetos que no son lo que queremos que identifique. Le mostramos muchas imágenes y le indicamos, en cada caso, qué es correcto y qué no lo es. El robot aprende a partir de patrones, identificando características comunes que aúnan los animales a identificar.
Sobre esta base, a partir de la actividad, se propone un debate sobre el primer gran concepto incluido en un proceso de entrenamiento: ¿qué es un patrón? ¿Alguien sabe? ¿Quieren buscar la definición? ¿Quieren charlarlo y comentarlo?
-
Diferencias entre personas y motores de IA. Los programas de IA pueden seleccionar personas y objetos en segundos, debido a su capacidad para seguir instrucciones y reconocer patrones con una gran cantidad de información y datos. Si un ser humano tuviera que distinguir personas y objetos a gran escala en forma manual, esta tarea le llevaría una cantidad de tiempo enorme, por lo cual sería materialmente imposible de realizar. Por el contrario, en el caso de la IA, se van conformando patrones de manera veloz aun teniendo una cantidad vastísima de datos; incluso, como se observa en el juego del pez, el volumen de datos mejora el resultado de la selección.
Tiempo y cantidad
Imagínense que cargamos solo treinta peces, pero si hubiéramos puesto, por ejemplo, la base mundial de animales acuáticos, habría sido imposible para un ser humano definir qué es un pez o qué no lo es, sacar patrones y hacer un modelo, por la cantidad infinita de información. Como indicamos antes, la IA, en cambio, puede procesar enorme cantidad de datos e información muy velozmente. De hecho, resulta importante señalar que lo que mejor hace la IA es procesar mucha información en poco tiempo.
La máquina descubre y define patrones procesando la información, sacando conclusiones para identificar el elemento en cuestión, delimitando características (tiene aletas, no tiene aletas, por ejemplo). Sigue paso a paso el mecanismo de identificación, atiende a lo que se repite, lo que se reconoce en cada uno de los elementos.
Volviendo sobre la actividad anterior, se pueden reconstruir las instrucciones dadas a la máquina a partir de las acciones de quienes jugamos (indicando qué es un pez y qué no lo es). Se puede inferir que, al determinar que algo no es un pez, se están definiendo instrucciones para reconocer objetos según su forma, color, partes, etc.
Proponemos preguntar a los y las estudiantes si saben o escucharon hablar alguna vez de algoritmos. A partir de lo que vayan diciendo, se irá conceptualizando y definiendo la noción.
Un algoritmo es un conjunto de instrucciones que convierte algo (una entrada) en otra cosa (una salida). Es una secuencia, una serie de instrucciones sistemáticas que permite a un programa dar una respuesta. Podríamos decir que son como los pasos de una receta.
Si volvemos a revisar el juego del pez, vemos que cuando ponemos a funcionar el robot, en algunos casos se producen errores (entre los peces, el robot ha dejado pasar otros objetos que no lo son). Esto significa que la IA es falible, lo que se remedia en alguna medida entrenando más al programa, es decir, ampliando la base de datos inicial (más peces y otros elementos).
Para profundizar sobre este tema, analicemos un caso real de uso de la IA para la producción de sustancias alimenticias. La protagonista es la empresa chilena NotCo, que se dedica a desarrollar alimentos con base en vegetales.
El color de la leche NotMilk
Para elaborar leche se le dio al programa una indicación: «Vamos a hacer una receta de leche», un listado de elementos, sugerencias y acciones que incluían recetas y características del producto. El objetivo era que el programa propusiera recetas que, con los ingredientes deseados, resultaran iguales a la leche de vaca.
Lo que hizo la IA fue separar aquellos ingredientes que se le señaló que eran aptos para una leche, o sea, seleccionó ingredientes, consistencia y procesos entre las variables que se le dieron, definió patrones y los combinó de manera tal de lograr una gran variedad de leches. Ese fue su proceso para desarrollar un algoritmo: seguir las instrucciones a partir de patrones y de entender que ciertos ingredientes, consistencia y procesos hacen a la leche y otros ingredientes, consistencia y procesos no hacen a la leche.
El programa de IA utilizado entregó muchas fórmulas para leches, todas muy aceptables, salvo por un detalle: el color. Todas las fórmulas produjeron leches de color morado.
¿Por qué habrá sido?
Es interesante pensar junto con los y las estudiantes qué sucedió en el caso de NotCo. ¿Por qué la IA no pudo producir leche con el color habitual? ¿Este dato estaba en la información que el programador le había suministrado a la IA? A partir de estas preguntas, se espera que los y las estudiantes puedan inferir que el color de la leche no estaba en la información que había sido ingresada al sistema. No era una de las variables o categorías incluidas en el entrenamiento, motivo por el cual esta variable nunca fue incluida por la IA en su algoritmo.
Podríamos decir, entonces, que faltaron datos. La IA no aprende sola ni de sí misma. Si se excluye algún elemento en la base de entrenamiento inicial, será imposible que logre identificarlo. A la IA de NotMilk le dieron ingredientes, consistencias y procesos, pero ninguna variable que indicara sobre la categoría «color». Si volvemos sobre el juego de los peces, podríamos preguntarles a los y las estudiantes si piensan que la IA podría identificar con los datos que le dimos, por ejemplo, un gato. El análisis debe llevar a una respuesta similar a la producida en torno al ejemplo de NotMilk: la IA no podría identificar un gato porque no incluimos imágenes de gatos en su información. De esta manera, no podría comparar con nada como para detectar patrones.
Entonces, ¿cuán importante es la selección de la información con la que «alimentamos» a una IA? Es ciertamente nodal porque, como vimos tanto en el ejemplo de NotMilk como cuando analizamos nuestro juego con los peces, si no le brindamos toda la información necesaria, la IA incurre en errores. A esto se llama «sesgo».
Según la RAE, sesgo significa: «Error sistemático en el que se puede incurrir cuando al hacer muestreos o ensayos se seleccionan o favorecen unas respuestas frente a otras».
La IA actúa sobre la base de lo que aprendió de las experiencias que le enseñamos los seres humanos. Podrá inventar muchas «leches», pero si no le cargamos un dato la IA no lo repone. Si en la información para las recetas de leche no se le hubiera cargado, por ejemplo, azúcar, ninguna de las combinaciones de leche tendría azúcar. La IA releva, ¡pero no inventa! De esta manera, sus respuestas pueden estar sesgadas.
La ausencia de información genera el desarrollo de resultados limitados, sesgados. Es importante incluir información lo más completa posible y específica para evitar errores. En este caso, hablamos del color de la leche, pero el acto de sesgar se implica, con la IA, en temas más importantes como en lo relativo a la responsabilidad y a la ética.
Como sugerencia, para profundizar la comprensión sobre el concepto de sesgo los y las invitamos a leer sobre el caso de la compañía Amazon, que abandona la contratación de un proyecto de IA por su sesgo sexista.
Amazon tenía, evidentemente, un software de IA que no era neutral, poseía un sesgo: no contaba en su base de datos con currículums de mujeres, solo de hombres. El input era, así, limitado. Por consiguiente, el aprendizaje fue limitado. Esto es lo que se denomina justicia algorítmica.
El concepto de sesgo es una de las líneas más importantes para trabajar en la escuela con IA. Porque no hay que olvidar que son los seres humanos o las instituciones 一integradas o lideradas por personas一 los que cargan la información de las bases de datos de los sistemas de IA. Por eso es importante señalar que la IA nunca es racista o misógina, en todo caso, el racismo, la discriminación o la misoginia están en el ser humano o en el contexto social que genera los datos que la entrenan.
Tercer momento: ¿Cómo se arma un modelo?
Sugerimos realizar otro juego, que apunta a entrenar un motor de IA para que funcione como modelo clasificador, con algunas imágenes etiquetadas, por ejemplo, colores. Este modelo, una vez entrenado, será capaz de predecir si frente a la cámara web cree que hay un color u otro.
Para ello, vamos a hacer dos secuencias de fotos. En la primera, realizaremos fotos con papeles de un color y, en la segunda, con papeles de otro. Nuestro objetivo es enseñarle a la máquina a identificar esos dos colores.
En este ejemplo, utilizamos el aprendizaje no supervisado, es decir que nosotros/as cargamos los datos de entrada. No ocurrió lo mismo en el caso de la clasificación de los peces, porque en ese juego estos ya aparecían, estaban dados.
Les proponemos jugar a Teachable Machine, una herramienta de IA desarrollada por Google que hace que la creación de modelos de aprendizaje automático sea rápida, fácil y accesible.
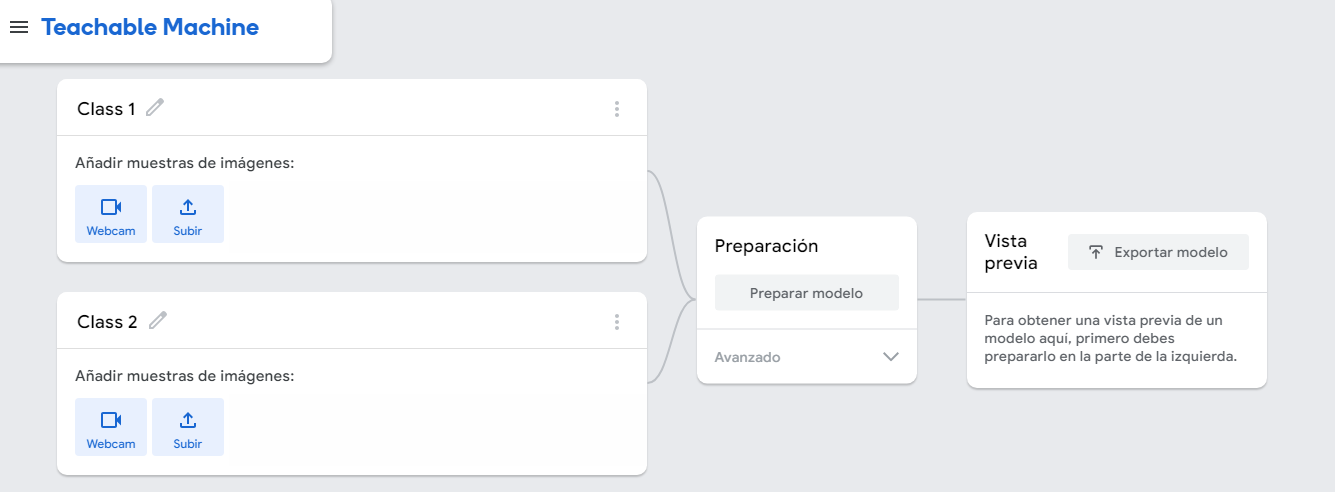
Cuando ingresamos a la aplicación, vamos a definir etiquetas, es decir, cargar las clases de objetos que queremos que nuestro modelo reconozca, con fotos que tomaremos con la cámara web. Para facilitar la tarea de reconocimiento, conviene utilizar un fondo sin detalles; y como solo va a reconocer las etiquetas que le indiquemos, una buena idea es agregar también fotos del fondo solo, sin los papeles coloreados (así, el modelo podrá detectar la ausencia de colores).
Una vez cargada la información, presionaremos el botón Train Model (‘Preparar modelo’) y esperaremos a que se complete el entrenamiento sin cambiar de pestaña.
En este caso, la aplicación muestra con qué grado de seguridad (mediante una barra de porcentaje que nos aparecerá debajo de Vista previa) infiere que el objeto que está frente a la cámara es un papel de un color o un papel de otro color, solo de aquellos colores que hemos cargado. Recuerden que aquello que no le mostramos, no le «enseñamos», no lo puede «adivinar».
Cuarto momento: La IA no es tan inteligente
Como mencionamos al principio, hay muchos ejemplos de IA. Y aunque se la viene investigando y desarrollando hace muchos años, ahora todo el mundo habla de ella.
Están los bots conversacionales que, seguramente, nuestros/as estudiantes (y, por qué no, los y las docentes también) ya han usado, como, por ejemplo, el ChatGPT.
Probemos con una app similar, Gemini, de Google.
Podemos proponer a los y las estudiantes que al ingresar le soliciten a Bard que cree una poesía sobre el tema «ojos». El tipo de poesía que la IA generativa produce es similar al siguiente ejemplo:
Ojos
Ojos negros, ojos azules,
Ojos verdes, ojos miel,
Cada mirada es un mundo,
Un universo a descubrir.
Ojos que reflejan el alma,
Ojos que expresan el corazón,
Ojos que sonríen y lloran,
Ojos que hablan sin hablar.
Ojos que ven la belleza,
Ojos que ven el dolor,
Ojos que son ventanas al alma,
Ojos que son puertas al amor.
Dedicamos un tiempo a escuchar los poemas producidos por la IA. Si analizamos este ejemplo, veremos que las imágenes que la IA produce son bastante estereotipadas y carentes de imaginación. Su estructura es algo anticuada y las palabras elegidas, un tanto trilladas.
A continuación, podemos comparar el poema generado por la IA con un poema referido a los ojos, como Tus ojos de Octavio Paz, que maneja recursos con una dimensión poética más elaborada.
¿Por qué les parece que hay tanta diferencia entre uno y otro poema? ¿Cuál les resulta más creativo? Probablemente los y las estudiantes arriben a la conclusión de que el poema escrito por Octavio Paz maneja las palabras de un modo más profundo, con una mirada más compleja. Esto es así porque la IA trabaja con la reformulación de la mayoría de los datos con los que cuenta. La IA hace una especie de mashup, edita y mezcla de alguna manera versos de distintos poemas (en el caso de nuestro ejemplo) para producir el poema que entrega como resultado. Es solo una mezcla automática sin la conciencia del acto creativo, que quienes se dedican a hacer mashup o remix sí tienen.
Como venimos sosteniendo a lo largo de este taller, la IA no inventa sino que copia.
Tampoco es capaz de responder sobre sensaciones o sentimientos, puesto que carece de esta información. Si le preguntáramos cómo se siente un pollito recién nacido, solo podría responder aquello que ha buscado y que contesta automáticamente (por ejemplo, es suave, plumoso, amarillo). Por supuesto, no es que la IA haya «sentido» esas sensaciones. En internet hay audio e imagen para que el chat «recoja», pero no hay aún sensaciones o sentimientos.
Quinto momento: Sugerí, entrená, comprometete
A partir del recorrido que hemos hecho, les proponemos construir en forma conjunta una carta abierta a una persona que entrena máquinas sobre el uso responsable de la IA.
¿Qué le podríamos sugerir o recomendar? ¿A qué cuestiones creen que es necesario prestarle atención para que la IA sea utilizada con responsabilidad?
Luego de debatir con el grupo total y acordar sobre los puntos que se consideran nodales a la hora de pensar en la IA desde una mirada crítica y ética, una posible forma de llevar a cabo esta actividad, y seguir expandiendo la experiencia, es que los y las participantes graben sus reflexiones en una de las tantas app que convierte texto en audio. Por ejemplo, podemos utilizar TTS Maker, que es una app hecha mediante IA. Luego de grabarlo, el archivo puede ser bajado en formato .mp3, subido a Spotify y viralizado en redes.
Asimismo, podemos invitarlos/as a compartir sus recomendaciones en otros formatos en otras redes sociales: realizar un reel para Instagram, un tiktok o escribir un hilo en X.
Recomendados

Talleres «Conectar Joven»
Colección
En esta colección se comparten diversas propuestas dirigidas a los y las jóvenes para trabajar sobre temáticas relevantes y de interés para ellos y ellas, tales como inteligencia artificial, videojuegos, arte digital y participación juvenil, atravesando nuevas experiencias de conocimiento y de exploración tecnológica.

Debates sobre inteligencia artificial: de la ficción a la realidad
Colección
La IA está presente en nuestra vida cotidiana y su rápida evolución está generando grandes transformaciones. ¿Qué es la IA? ¿Cómo funciona? ¿Se la puede utilizar en educación? Compartimos una serie de materiales en diferentes formatos que abordan estas y otras preguntas, para reflexionar y nutrir el debate.

Inteligencia artificial, no te tenemos miedo
Libro electrónico
Una guía de actividades para abordar la inteligencia artificial en las escuelas y espacios culturales, con el objeto de conocer y «desarmar» los procesos sobre los que trabaja esta nueva tecnología.

¿Qué es EducarLab?
Texto
En esta nota se presentan las diferentes modalidades del proyecto EducarLab y las diversas líneas de trabajo que aborda a lo largo del país.
Ficha
Publicado: 06 de noviembre de 2023
Última modificación: 09 de abril de 2024
Audiencia
General
Área / disciplina
Educación Digital
Nivel
Secundario
Ciclo Básico
Ciclo Orientado
Categoría
Actividades
Modalidad
Todas
Formato
Texto
Etiquetas
ConectarLab
inteligencia artificial (IA)
algoritmo
huella digital
Autor/es
Educ.ar
Licencia
Creative Commons: Atribución – No Comercial – Compartir Igual (by-nc-sa)